There are times in our data science journey when we’re in the process of applying regression (whether linear or logistic) and we reach the crossroads of electing between model complexity and goodness of fit.
We’ve all been there. Where the feeling of discombobulation settles in and the questions rain down:
- how do we decide between models?
- how do we decide which variables to keep in our model?
- how do we toe the line between casting too simple vs. too complex a model?, and
- how do we decide between whole models that may contain completely different variables?
Founded on information theory, formulated by statistician Hirotugu Akaike in Japan, and announced in English in 1971, the Akaike Information Criterion (AIC for short) has since become a fundamental statistical paradigm and oft utilized Data Science concept.
It turns out we can have our cake and eat it too. The AIC value permits us to deal with model complexity and goodness of fit in one fell swoop.
What is the AIC value?
The AIC value is a measure of goodness of fit that favors model simplicity.
What this means is that we don’t allow our model to become more complex unless the added complexity improves our model. We don’t add variables unless they’re pertinent.
Being that the AIC value provides a measure of the relative quality of statistical models for a given data set, we utilize it as a means of model selection. To determine which variables should be included in our model and which model is the best for our dataset.
AIC can be defined with the following equation:

Where k represents the number of model variables and ln(L) represents the log likelihood.
A few notes on log likelihood:
- Likelihood (L) is a measure of how likely we are, given a model, to see our observed data.
- We take the natural log (ln) of our likelihood (L) value for computational ease. Taking the natural log of our likelihood (ln(L)) scales the resulting value to a more manageable range (ie. ln(10) → 2.303, ln(100) → 4.605, ln(1000) → 6.908).
- AIC uses a model’s log likelihood as a measure of fit, with a higher value indicating a better fit.
We want a lower AIC value. A lower AIC value is indicative of lower information loss and a stronger model.
When we add variables to our model (k increases), our AIC value increases. Whereas when we increase our log likelihood (ln(L), our AIC value decreases.
This is where the “magic” happens.
The model with the lowest AIC value is interpreted to strike the best balance between fitting our dataset while avoiding over-fitting.

When do we apply AIC?
Interpreting AIC values is most commonly used for model selection when we don’t have access to out-of-sample data (ie. a test set).
When we’re limited dataset-wise, training on all the data and then using the AIC value can result in improved model selection vs. the more traditional (machine learning) train-test-split approach.
It’s also worth noting that when we’re dealing with small sample sizes, for example sizes where the ratio of data points to number of parameters (k) is less than 40, it may be preferred to use AIC’s small sample equivalent, AICc:

Or the more stringent Bayesian Information Criterion (BIC):
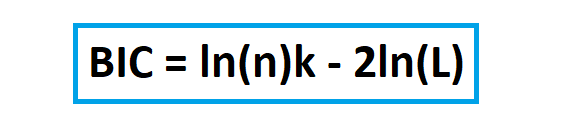
These adaptations of the AIC equation, reach a greater level of precision since there’s a “correction variable”. The AICc and BIC equations account for sample size with the inclusion of the n variable.
We live on an island surrounded by a sea of ignorance. As our island of knowledge grows, so does the shore of our ignorance. — John Archibald Wheeler
Use of the AIC value is easy to apply, interpret, and explain.
It solves the problem of electing between the left fork (model complexity) and the right fork (goodness of fit), by blazing a path straight through the brush (choosing both).
Simplicity is one of its major strengths. It provides a great metric for model selection that is especially useful when we don’t have access to out-of-sample data.
With that said, it’s not the only metric, and for many situations a combination of the AIC value with other metrics (ie. t test or F test) or electing a more advanced measure altogether (ie. DIC or WAIC) is preferred.
Now that we know a bit more about the AIC value, we see clearer how little we actually know. In Data Science, as in life, that’s just the case with learning. We carry on, learning more only to realize how little we know.
Thank you for reading!
Where to from here?
Below is a short list of resources for more background info regarding AIC and its application:
- For more on likelihood, check out StatQuest.
- For a brief intro to AIC vs. AICc vs. BIC: check out Dr Jono Tuke’s video.
- For AIC applied in Python, check out this TDS article. Scroll down.
- For advanced model selection methods (DIC, WAIC, LOO-CV), check out Ben Lambert’s video.
